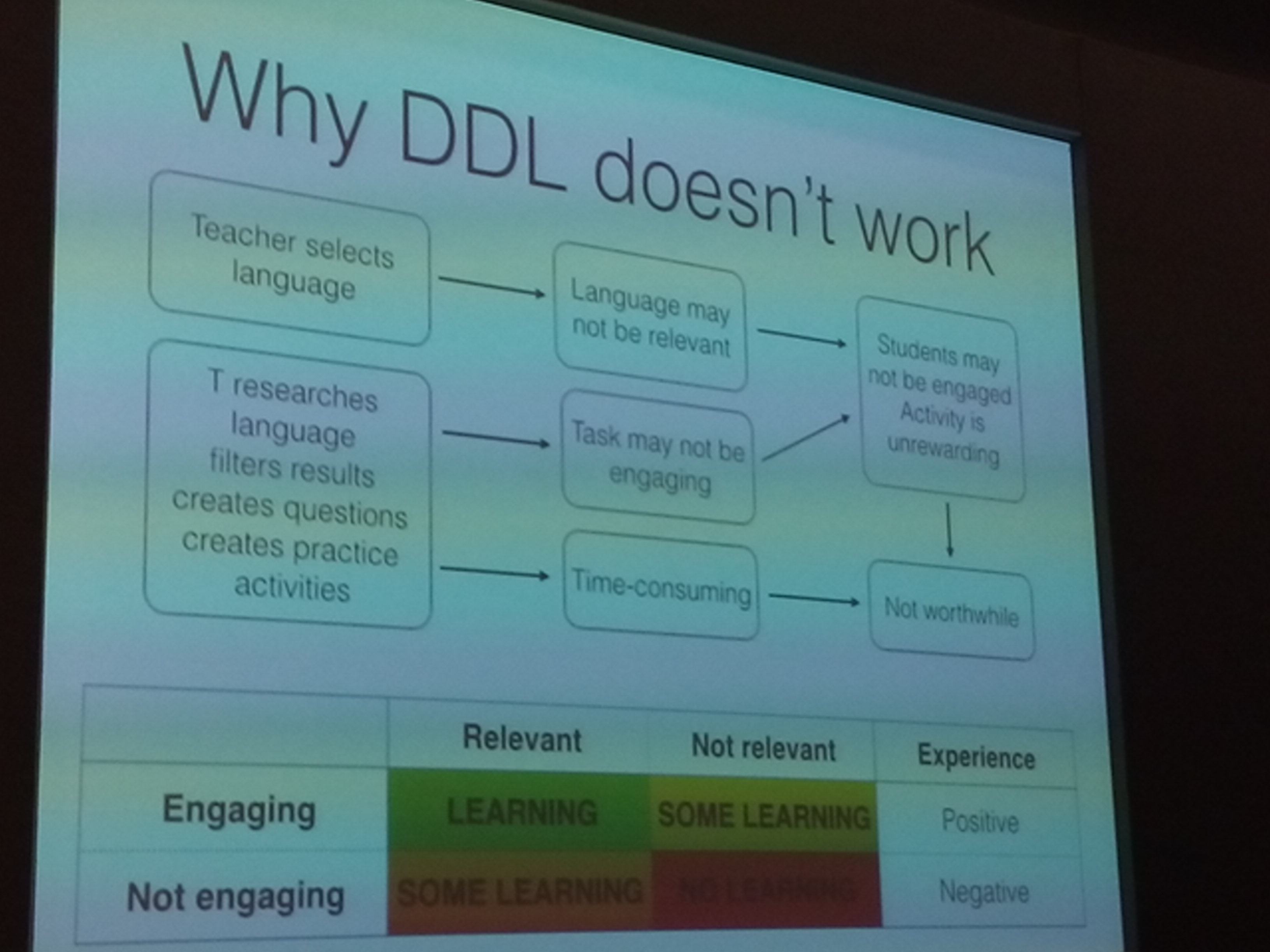
Another addition to my collection of write-ups based on the talks recorded by IATEFL Online and stored on the website for everybody to access. What a wonderful resource! This one is by Michael McCarthy, and, as you would expect, is based on corpora and vocabulary – this time in the context of academic spoken English…
MM starts by saying it is easier to study academic English in its written form and much more challenging in its spoken forms. His main point is that there is no one single thing that we can call Spoken Academic English. His talk will draw on information from corpora and show how it can be used in materials. He is going to use a corpus of lectures, seminars, supervisions and tutorials from the humanities and the sciences, the ACAD, and a sub-corpus the Michigan Corpus of Academic Spoken English, MICASE. He is also going to be using from the CANCODE corpus the sub-corpus of social and intimate conversations. This is the data that MM used.
Corpora are widely known and accepted in our profession, so MM didn’t need to introduce what they are and why we use them. He looked at a frequency list of words, the simplest job you can do with a corpus. You can also do keyword lists, which tells you more than just if something is frequent: it tells you whether it is significantly statistically frequent or the opposite, significantly statistically infrequent. We can also look at chunks and clusters, the way words occur together repeatedly. We rarely go beyond 5 or 6 words, due to the architecture of the human mind. Chunks are most common in the 2-4 word chunk-size. Dispersion is another thing to consider, in terms of the consistency of words being used, to know whether a particular text or genre is skewing the data.
In the spoken ACAD, in the top 50 frequency list, there are lots of the usual conversation markers, lots of informality, lots of you, I, yeah, er, erm. There are lot of familiar discourse markers, such as right and ok, and response tokens, i.e. the words or sounds used to react. The most frequent two word pragmatic marker in ordinary social conversation is you know – 66% of the occurrences of the word ‘know’ are in the form ‘you know/y’know and the picture looks the same in the academic corpus. This, however, is not the whole picture. We have something like everyday conversation but when we go into the keyword analysis, things become a bit more interesting. The top 20 keywords in spoken academic data are:

Now, a lot of familiar conversational items are present but also some that if your friends used them with you in everyday conversation over a cuppa, you’d lose the will to live. So there are words here that don’t have the informal conversation ring. Not least the preposition within which is right up there in the top 20. We will come back to which, terms and sense later.
Keywords tell us more than just what is frequent – they enable us to have a greater, more nuanced picture of how words are functioning in the data. We can find some interesting differences between conversational and academic spoken English: If we do a straight frequency count, the discourse marker “ok” comes out higher in a keyword list than the frequency list, in the academic spoken English corpus.

MM found that 95% of the “ok” in the data are either response tokens e.g. that’s ok, well, ok or discourse markers signalling phases e.g. “ok let’s go on to look at <something else>“. They are used overwhelmingly by the lecturers or tutors. MM had a PhD student with an annoying habit: after exchanging pleasantries, the student would say “ok, now I want to talk about…” and then once they had, he would go “right, ok..” – MM thought it should be HIM saying those phrases. Students very rarely respond with “right, ok“. So in academic speaking, we are looking at a different set of discourse roles than in conversational English, that is what the corpus is showing us. The roles are directly related to the language. Some items that are present in the frequency list disappear in the key word list, i.e. fall too far down the list for MM to be prepared to go through and find them e.g. well, mm, er, you. This negative result says that these words do not distinguish academic speaking from any other kind of speaking. However, some of the language is particular to the roles and contexts of the academic set-up.
MM says it takes a long time and a lot of hard work to actually interpret what the computer is trying to tell you. It is dispassionate: no goals, prejudices, aims or lesson plans. It just offers bits of statistical evidence.

What struck MM when he looked at this list is that on the conversational side, at least 3 and possibly more of these are remarkably vague. It surprises people that there is a great degree of vague category markers that come up to the top of this spoken academic discourse, but it shouldn’t because the student is being nurtured into a community of practice and in any community with shared values/perspectives/opinions, you don’t need to specify them. You can simply say x, y, etc or x, y and things like that. This presence of the vague category markers is crucial – not only do you have to hear and understand them but you have to be able to decode their scope, and know what the lecturer means when they say them. Vague category marking is something that is shared with everyday conversation but the scope is within academic fields.
At no. 18, “in terms of the” – not surprising because in academia we are always defining things in terms of something else, locating pieces of knowledge within other existing/known knowledge – the discipline as a whole or a particular aspect of it. It is much more widely spread in academic spoken discourse compared with conversational:

MM goes on to look at the consistency, or spread of items across data – looking for things that occur in a great number of texts. In social conversational data, the dispersion of I and you is consistently high. The picture in academic spoken English is different:

The pronouns are reversed – you is more frequent than I. This brings us back to the fundamental business of roles: most of academic discourse is about telling “you” how to do things and become part of the community of practice. Thinking back to the chunks “you can see” etc. A transmissive you. However, we do notice there is quite a bit of I in the academic spoken, it’s not remote. I is generally used by lecturers and tutors. But if we look across events, there is great variation. Even within two science lectures, in one there is a personal anecdote, so more use of “I” (more, even, than the informal guest speaker), in another not:

Here is a summary of the tendencies MM has covered:

The remainder of the talk is an advertisement for Cambridge University Press’s Academic Vocabulary in Use book, which draws on what is learnt from the data, trying to capture the mix of chatty conversational items and items that are very peculiar to the academic discourse. The best grip on spoken academic discourse is through understanding the discourse roles of the tutors and the students, which influence how they speak – i.e. differently. They will use certain keywords and chunks, but the labels (e.g. lecture, seminar, supervision) used for speech events are a very imperfect guide of what will be included there.
This was a fascinating talk, one I’m glad I’ve finally caught up on! I always find it interesting to see how corpora are used and what is discovered in the process. Nice to see the “in terms of” chunk in there – it reminds me of my first year at the Sheffield University International Summer School, where during the induction Jenifer Spence – author EAP Essentials and leader of the theory side of our induction programme that year – spent a fair bit of time hammering the importance of “in terms of” into us: we were always to be asking, and encouraging students to ask/consider, “in terms of what?” in relation to whatever it was that they were writing or saying! I had never considered how odd it would sound in an informal chat though, as per MM’s example “How was your holiday?” “Well, in terms of the accommodation…” – not really! Unless you felt like being particularly pompous, I suppose…